

Jako programiści lubimy dyskutować nad tym, czy nasz kod wygląda dobrze. Zastanawiamy się, czy da radę go re-używać oraz zrozumieć. Niestety, nie podejmujemy zbyt wiele dyskusji na temat tego, czy aplikacje, które tworzymy mają odpowiedni performance. Zatem dziś jak podejrzewacie, będzie właśnie o performance.
Zwinne programowanie w praktyce
Agile jest metodologią, która ma wiele zalet. Klient widzi aplikację w trakcie procesu developerskiego, może kontrolować swoją wizję i potrzeby. W trakcie takiego developmentu my traktujemy pracę zadaniowo. I klient również tak ją traktuje. Dowozimy kolejne ficzery, prezentując je w międzyczasie na cotygodniowych demkach. Jesteśmy dumni z siebie, bo jutro piątek i pierwszy deploy produkcyjny 😉 Bo klient tak napompował aplikację marketingowo, że innego terminu na deploy nie ma. A wcześniej się nie da, bo dowozimy ostatnie sztuki kodu.
Jest piątek, godzina ósma. Lecimy z tematem. Wrzucamy tzw. zaślepkę „Zaraz wracamy, zmieniamy się dla Ciebie” i lecimy z migracją (bo to migracja z jednego rozwiązania na drugie). Wszystko wcześniej było przeklikane, logika migracji działa. Godzina dziewiąta, devops od strony klienta podsyła nam dane do zmigrowania. Jest to kilka plików, największy, prawdopodobnie z historią zamówień, ma pewnie z gigabajt. Odpalamy import i… czekamy. Leci jedna godzina, druga. Zaciekawiony klient dzwoni i pyta „Jak tam leci? Zaraz startujemy, co?” a zespół mu odpowiada „mamy dopiero 40% migracji zrobionej”. Niesmak ze strony klienta rośnie, bo miało pójść szybko.
W okolicach godziny trzynastej migracja się skończyła, klikamy aplikację przed ściągnięciem zaślepki. I nie wiadomo, czy śmiać się, czy płakać. Bo homepage odpala się siedemnaście sekund (bez ruchu klientów na sklepie), a strona kategorii produktów w ogóle nie chce się odpalić – dostajemy timeout serwera HTTP. Dalej tej historii toczyć nie będę, ale myślę, że każdy z Was wyobraża sobie, jak wyglądały kolejne minuty, godziny, weekend i tygodnie.
Performance aplikacji też jest ważny
W przedsięwzięciu zespołu developerskiego nigdy celem samym w sobie nie powinno być dowiezienie funkcjonalności, aby klient ją zaklepał na demku. Najważniejszy jest sukces biznesowy. Koniec końców, aplikacja ma działać na produkcji. Ma się skalować, ma spowodować, że każdy kto ją odwiedzi, będzie zadowolony. Na tyle zadowolony, że chętnie wyłoży swoje pieniądze. Niezależnie od tego, czy jest to sklep internetowy, platforma e-learning, czy narzędzie typu SaaS. Jeżeli aplikacja komuś się ładuje 5 sekund co żądanie, to niemal pewne, że zrezygnuje. I nie, nie uważam, że Agile czy Scrum są niedobre. Mają one swoje zalety biznesowe. To my, programiści, już w procesie developmentu powinniśmy zadawać sobie wzajemnie w zespole konkretne pytania i odpowiadać na nie tak, aby nie było potem miejsca na zbyt duże poprawki. Bo w rzeczywistości zbyt wiele miejsca na to nie będzie.
Ważnym aspektem performance jest to, że mówi się, aby nie próbować optymalizować platformy na siłę. Mówi się wtedy o tzw. preoptymalizacji i potocznie mówi się o niej, że jest złem. I w sumie to jest ona złem. Bo jeżeli ktoś mówi już na starcie projektu, że tutaj i tutaj zrobimy cache, to to jest złem. Bo trzeba pisać kod tak, aby nie planować wrzucenia cache wszędzie, gdzie się da. Podobnym złem będzie na siłę zamiana Doctrine ORM na DBAL, bo „jak sami napiszemy zapytania, to będziemy mieli lepszą kontrolę nad bazą danych”. Koniec końców okaże się, że dla performance poświęciliśmy design kodu, który również jest istotny.
Zamiast tak kombinować, powinniśmy znać podstawowe heurystyki związane z performance aplikacji i stosować je w pracy codziennej. Powinniśmy również znać narzędzia, z których korzystamy, zamiast pozbywać się ich, twierdząc, że są złe. Bo tak myślący ludzie nigdy nie przesiedliby się z dorożek do samochodów spalinowych.
Po tym nieco długawym, choć w mojej opinii ważnym wstępie, możemy przejść do tej ciekawszej części wpisu 🙂
Wydajność aplikacji z perspektywy PHP i Symfony
Wszystkie poniższe punkty zakładają, że pracujemy na dosyć standardowym stacku: Symfony, Doctrine, jakiś MySQL i Twig. Istnieje jednak prawdopodobieństwo, że część z tych problemów może być znana również z innych frameworków.
Faworyt dzisiejszego dnia: Doctrine N+1
Ten problem jest chyba najgorszym z najgorszych. Często tak na prawdę nie zdajemy sobie sprawy z jego istnienia. Podczas developmentu korzystamy z Doctrine tak, jak Pan Bóg przykazał – mamy encje, relacje. Mamy QueryBuildera, repozytoria. Wrzucamy jedną główną encję do widoku, a pozostałe rzeczy z niej sobie wyciągniemy. Nie zdajemy sobie sprawy z tego, że np. dla wygenerowania listy 20 produktów, Doctrine będzie generował… 1000 zapytań? Jest to prawdziwy zabijacz aplikacji.
Rozwiązaniem problemu N+1 jest optymalizacja, która polega na tym, aby nie korzystać z mechanizmu lazy-loadingu, który w Doctrine jest opcją domyślną. Jeżeli wczytujemy jakąś encję, z której następnie będziemy wyciągali sobie kolejne relacje, to znaczy, że powinniśmy zmusić Doctrine, aby załadował wszystkie potrzebne encje „w miejscu”. Bardzo szeroko poruszyłem ten problem w innym moim wpisie: Doctrine i problem Lazy Loadingu. A we wpisie Jak i kiedy działa Doctrine Eager Loading? przedstawiam sposób na to, aby sobie z tym problemem poradzić 🙂
Ogranicz komunikację z innymi systemami
Drugim potencjalnym problemem, który zajeżdża nasze aplikacje jest blokowanie requestów przez komunikację z innymi systemami. Jeżeli np. macie w aplikacji strony, które wymagają komunikacji w trybie GET (np. pobieranie stron z zewnętrznego CMSa), to wyobraźcie sobie, że każdy odwiedzający stronę będzie musiał czekać sporą ilość czasu na zaserwowanie informacji, które prawdopodobnie w krótkim okresie czasu się nie zmienią.
Rozwiązań tego typu problemów jest co najmniej kilka:
- Możemy wdrożyć wspomniany wyżej cache (w tym miejscu to akurat może mieć sens ?). Pamiętajmy tylko, że nie każdy system, od którego zależymy, może mieć możliwość inwalidacji takiego cache.
- Jeżeli jest taka możliwość, to dlaczego by nie postawić obydwu aplikacji na tej samej bazie danych? Albo podpiąć się naszą aplikacją pod drugą bazę danych i na tym poziomie wyciągnąć sobie potrzebne dane.
- Podłączmy się np. komunikacją kolejkową z tym systemem i zróbmy sobie duplikat potrzebnych nam informacji u siebie. Nie musimy za każdym razem wołać o dane do tzw. źródła prawdy. Możemy te dane trzymać u siebie, dbając równocześnie o to, aby aktualizować je w momencie, kiedy zmienią się one po drugiej stronie.
Każde z wyżej wymienionych rozwiązań będzie o niebo lepsze, niż nieustanna komunikacja z innymi systemami. Pamiętajmy, że PHP jest językiem jednowątkowym. Jeżeli wypuszczamy żądanie do innego systemu, to czekamy do momentu, dopóki ten system nam nie odpowie. A co, jeżeli ten system też będzie wołał pod spodem do innej aplikacji? Wtedy nasze linijki kodu będą czekały i czekały. A mogłyby nie czekać 🙂
Oddeleguj wszystko (co możesz) serwerowi
Wyobraźmy sobie, że mamy proces składania zamówienia w systemie. Oprócz zmian w tabeli zamówienia musimy:
- Wysłać informację do systemów ERP, magazynu i fakturowania
- Przeliczyć statystyki zamówień
- Zaktualizować indeks wyszukiwarki
To jest dużo zadań do zrobienia. Każde z nich ma dwie cechy wspólne: pierwsza to to, że są one zainteresowane miejscem w czasie, kiedy nowe zamówienie powstanie. Drugą wspólną ich cechą jest to, że nie muszą one być wykonane natychmiastowo po złożeniu zamówienia. Mogą one chwilkę poczekać.
W ekosystemie Symfony istnieje takie narzędzie jak Symfony Messenger, które służy m.in. właśnie do tego, aby delegować zadania mniejszego priorytetu do bycia wykonanymi „w tle” w sposób asynchroniczny. Polega to na tym, że na serwerze uruchamiamy dodatkowe procesy nazywane consumerami, które wyłapują takie zadania i je wykonują. Napisałem niedawno wpis, w którym pokazuję. jak można skonfigurować Symfony Messengera, aby pełnił rolę właśnie takiego „backgroundu serwerowego”. Tytuł tego wpisu to Symfony Messenger Asynchronicznie.
Uważaj na generyczne zdarzenia Symfony i Doctrine
Symfony oraz Doctrine mają taką świetną funkcjonalność, jak opcja nasłuchiwania zdarzeń. Mamy w środku takie zdarzenia, jak np. kernel.request, kernel.controller czy kernel.response (Symfony) lub postUpdate, postRemove oraz postFlush. Musimy sobie zdać sprawę z tego, że im cięższa logika znajduje się w listenerach nasłuchujących na te (takie) zdarzenia, tym gorzej dla naszej aplikacji.
Zdarzenia Symfony polegają na tym, że mamy jedno żądanie, w którym każde ze zdarzeń zostanie wywołane maksymalnie jeden raz (istnieją wyjątki, które przemilczę). Jeżeli zrobimy coś ciężkiego w listenerach nasłuchujących te generyczne zdarzenia, to musimy sobie zdawać sprawę z tego, że ta logika będzie odpalała się prawdopodobnie dla wszystkich (lub wielu) żądań. A może okazać się, że za każdym razem przed odpaleniem kontrolera będziemy wołać jakieś zapytanie z czteroma joinami i group by po to, aby sprawdzić, czy mamy odpowiednie uprawnienia do wyświetlenia strony. Niby idea zacna, ale jeżeli mamy duży ruch na stronie, to to zapytanie spowoduje, że baza danych pewnego dnia będzie chciała się na nas zemścić 😉
Zdarzenia Doctrine są nieco inne niż te z Symfony. One mogą się odpalać mnóstwo razy podczas jednego żądania. Ich główną charakterystyką jest to, że informują one o tym, że encja została utworzona, zmieniona lub usunięta. Aż kusi, aby w to miejsce wpiąć wysłanie żądania do innego systemu. Bo jak stan zamówienia został zmieniony, to my musimy wysłać informację do systemu kuriera. Gorzej, jeżeli ktoś w biznesie wymyśli sobie, że z aplikacji e-commerce robimy marketplace i jedno zamówienie będzie miało wiele przesyłek. Z jednej strony – biznes będzie zadowolony, bo to dalej działa tak, jak miało działać. Z drugiej strony płakać będą użytkownicy, którzy na finalizację zamówienia będą czekać wieki. Nie mają oni pojęcia, że to, że urządzają sobie swoją pierwszą restaurację powoduje, że kliknięcie „Zamów i zapłać” powoduje 15 dodatkowych żądań HTTP.
Unikaj sub-requestów w Symfony
Symfony jest frameworkiem bardzo elastycznym – daje wiele różnych możliwości swoim użytkownikom. Chyba wszyscy znamy ten schemat:
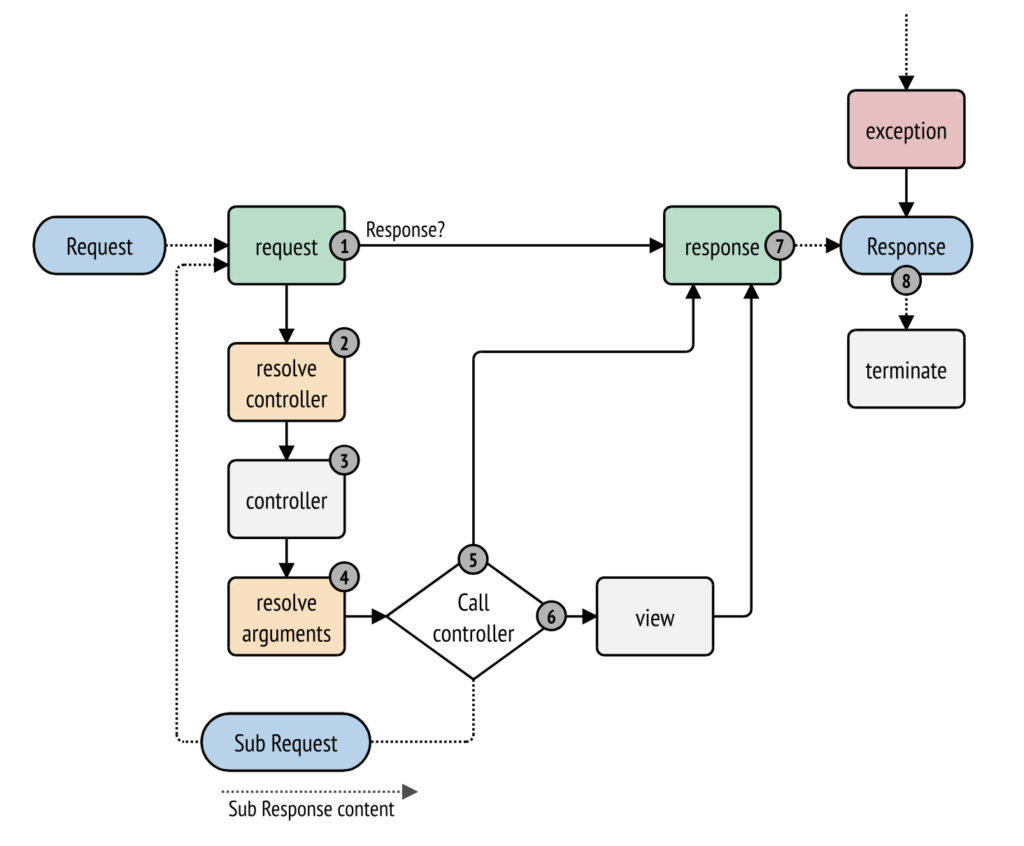
Mamy taki fajny ficzer, dzięki któremu możemy wykonywać żądanie w żądaniu. Bez ponownego bootowania Symfony. Jedni powiedzą, że fajne, a drudzi, że na co to komu. To teraz popatrzcie na taki kawałek kodu:
{% for product in products %}
{{ render(controller('App\Controller\Product::show', {'product': product})) }}
{% endfor %} Kochamy reużywalność. Do bólu kochamy 🙂 Bo skoro mamy zrobione wyświetlanie produktu, to dlaczego by tego nie wykorzystać do wyswietlenia pełnej listy produktów w ofercie? Przecież to ma nawet tak samo wyglądać. PM się cieszy, bo task zamknięty w godzinę. Klient się cieszy, bo grosza oszczędził. Devops się śmieje jak przegląda logi, a klient płacze jak musi coś kupić.
Nawet samo Symfony w swojej dokumentacji przyznaje, że tam dzieje się coś wiecej, niż wyłącznie odpalenie kontrolera 🙂 Jeżeli nie wierzycie, że tam pod spodem leci sub-request, to łapcie kilka referencji:
- https://github.com/symfony/twig-bridge/blob/7.0/Extension/HttpKernelExtension.php#L31 – tu mamy definicję funkcji
controller(...), a nieco wyżej definicja funkcjirender(...) - https://github.com/symfony/twig-bridge/blob/7.0/Extension/HttpKernelRuntime.php#L39 – tu mamy logikę zdefiniowanej wyżej funkcji
render(...) - https://github.com/symfony/http-kernel/blob/7.0/Fragment/FragmentHandler.php#L67 – tutaj dalsza logika funkcji
render(...), przeniesiona z paczkisymfony/twig-bridgedosymfony/http-kernel - https://github.com/symfony/http-kernel/blob/7.0/Fragment/InlineFragmentRenderer.php#L69 – tutaj domyślny renderer wykorzystywany w funkcji
render(...). Wskazana linijka tworzy sub-request.
No i mamy pod-żądanie 🙂 . Wywoływanie żądania w żądaniu samo z siebie nie jest takie złe. Czasami można coś tanio załatwić w taki sposób. W końcu po to to istnieje. No ale, jeżeli mamy 15 produktów na liście i dla każdego puszczamy osobny subrequest, to coś tu chyba jest nie tak. Możecie sobie pomyśleć, że przecież nikt mądry tak nie zrobi. Ale ludzie tak robią. Bo presja czasu, bo chcieli się wykazać, że znają mechanizmy Symfony. Albo właśnie presja czasu. I to niedobre jest.
Zamykaj transakcję bazodanową tylko raz
Nie rób flusha w pętli. Proszę. Błagam. Nie rób flusha gdzieś zakopanego w serwisach. Każdorazowe zapięcie transakcji bazodanowej w Doctrine powoduje, że:
- Doctrine musi przeliczyć, co w której encji się zmieniło
- Wygenerować odpowiednie zapytania
- Wysłać zapytania do bazy danych
- Uruchomić listenery nasłuchujące na odpowiednie zdarzenia.
Jeżeli macie gdzieś podpięte listenery na zdarzenie postFlush, to szczególnie musicie uważać na to. W ekstremalnych sytuacjach może okazać się, że jeżeli ta sama encja w kilku różnych transakcjach zmieniła się, to tylekroć Doctrine będzie musiał podjąć pracę nad tym wszystkim, co wylistowałem wyżej. Plus, jeżeli akurat na po tym flushu za każdym razem wysyłacie np. wiadomość na kolejkę, to będziecie mieli niepotrzebny spam na kolejkach. Nie licząc tego, że to wszystko wraz z wysyłką wiadomości będzie odbywało się w trakcie jednego żądania. A takich żądań może być wiele.
O robieniu flusha w serwisach pisałem kiedyś we wpisie o nieoczywistym tytule Czy możemy korzystać z FlashBaga w serwisach? Zachęcam Was bardzo do zapoznania się z nim 🙂
Pracuj na dużym zestawie danych – Nelmio Alice
Przykład z początku wpisu pokazuje, że mogliśmy zrobić to lepiej. Bo faktycznie, mogliśmy. Mogliśmy od razu pracować na dużym zestawie danych i na bieżąco weryfikować działanie platformy. Co nam szkodzi, aby załadować środowisko stagingowe dużą ilością danych i tam klikać nasze ficzery po wykonaniu. Informację o tym, że coś jest nie tak dostaniemy stanowczo wcześniej, niż w triumfalnym dniu deployu.
Na GitHubie istnieje świetne rozwiązanie, dzięki któremu możemy zaopatrzyć się w dowolnie duży zestaw danych. Mowa o Nelmio Alice. Jest to narzędzie wyspecjalizowane w generowaniu fixturek, czyli danych służących do testowania naszej aplikacji. Podczas procesu developmentu nie powinno nam zależeć na tym, aby mieć kilka sztuk encji z ładnymi zdjęciami. Powinno nam zależeć, aby mieć tak dużo egzemplarzy encji, aby wywalały aplikację wszędzie tam, gdzie coś można zrobić lepiej 🙂
Popatrzcie na przykład fixturki w Nelmio Alice:
App\Entity\Product:
product{1..100}:
code: 'test-code-<current()>'
name: 'Test name #<current()>'
price: <numberBetween(150, 200000)>
App\Entity\ProductAttribute:
productAttribute{1..100}:
name: 'Attribute #<current()>'
code: 'test-attribute-<current()>'
type: 'text'
position: <current()>
App\Entity\ProductAttributeValue:
productAttributeValue{1..100}:
attribute: '@productAttribute<current()>'
value: '<firstName()> <lastName()>'
product: '@product<current()>'A przykładowy kod na wczytanie takich fixturek wygląda następująco:
<?php
declare(strict_types=1);
namespace App\Command;
use Fidry\AliceDataFixtures\LoaderInterface;
use Fidry\AliceDataFixtures\Persistence\PurgeMode;
use Symfony\Component\Console\Command\Command;
use Symfony\Component\Console\Input\InputInterface;
use Symfony\Component\Console\Output\OutputInterface;
final class LoadFixtures extends Command
{
protected static $defaultName = 'fixtures:performance:load';
protected function configure(): void
{
$this->setDescription('Install test data for performance testing.');
}
protected function execute(InputInterface $input, OutputInterface $output): int
{
/** @var LoaderInterface $fixtureLoader */
$fixtureLoader = $this->getContainer()->get('fidry_alice_data_fixtures.loader.doctrine');
$fixtureFile = 'config/app/nelmio/performance/fixtures.yaml';
$fixtureLoader->load([$fixtureFile], purgeMode: PurgeMode::createNoPurgeMode());
return 0;
}
}Jak widać, nie jest to nic skomplikowanego. A zwiększanie ilości danych to bajka – wystarczy zmienić parametr w yamlu i po sprawie.
Comments are closed.